The Problem of Complex Data Relationships
A social media app struggled to recommend friends and analyze connections efficiently.
The issue? Relational databases were too slow for relationship-based queries.
The solution? Graph databases like Neo4j, along with other NoSQL alternatives like MongoDB, DynamoDB, and Time-Series DBs to optimize different workloads.
What are NoSQL Databases?
NoSQL databases provide flexible, scalable alternatives to traditional relational databases.
Key Benefits:
Schema-free: Allows dynamic data structures.
Scalability: Designed for high traffic and big data.
Optimized for specific use cases: Graphs, documents, key-value pairs, and time-series data.
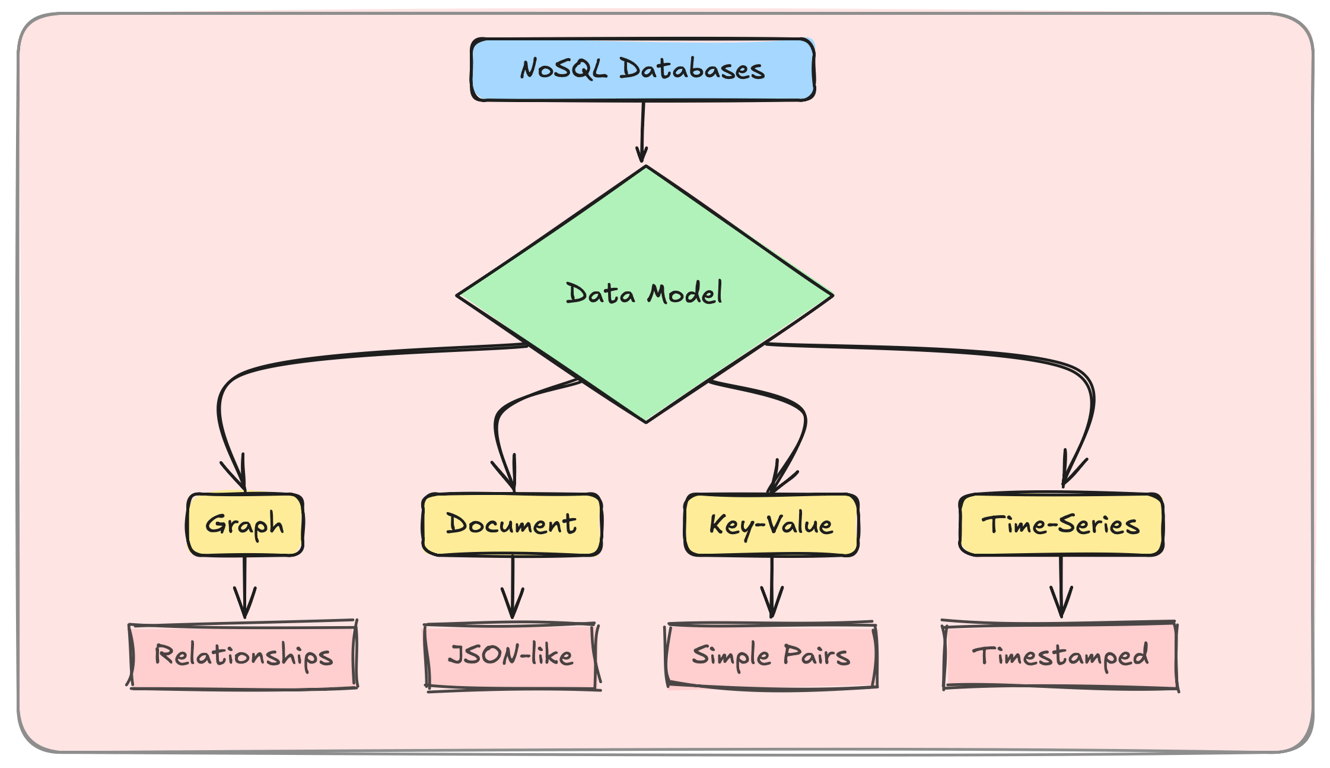
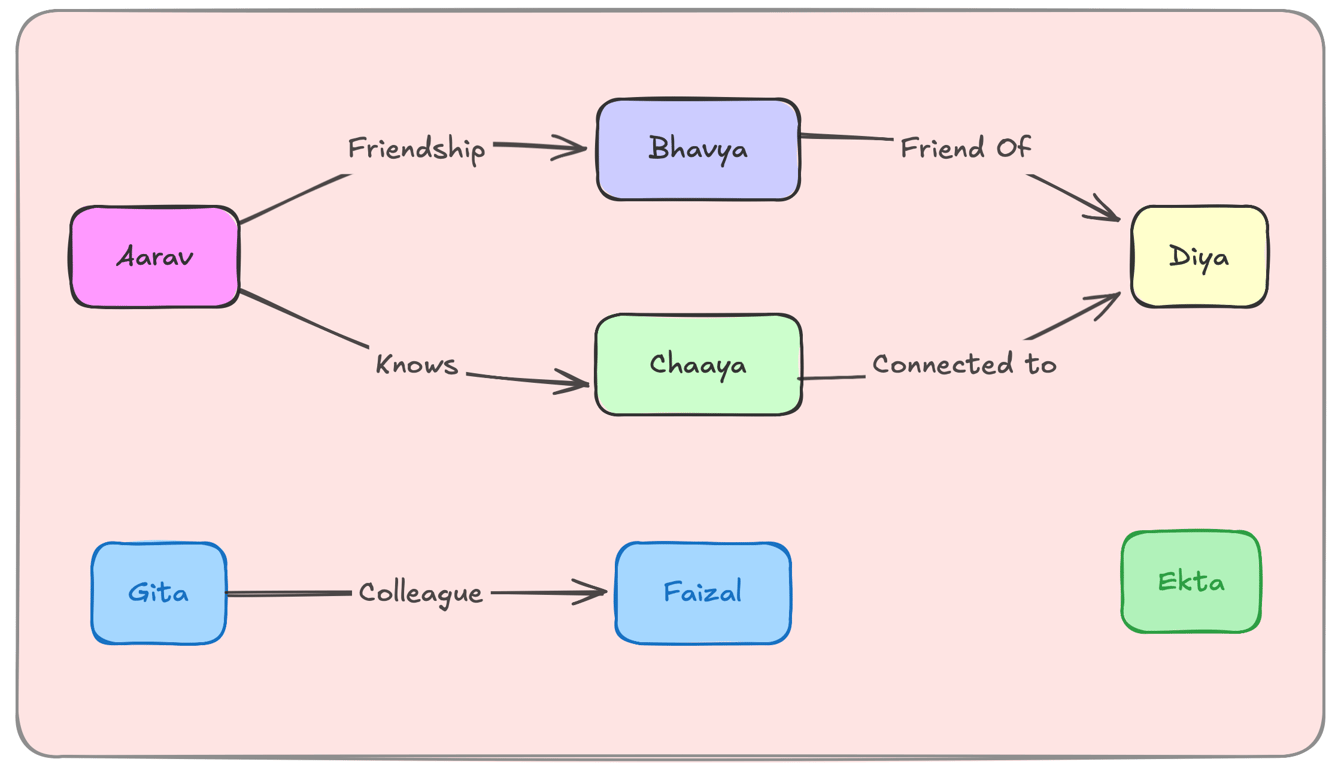
1. Graph Databases – Optimized for Relationships
Graph databases store data as nodes and edges, making them ideal for connected data.
Example: A social network where users, posts, and likes are interconnected.
Key Benefits:
Fast traversal of relationships (e.g., “Find friends of friends”).
Efficient pathfinding (e.g., shortest route in Google Maps).
Highly flexible schema for evolving networks.
Neo4j – The Leading Graph Database
Features:
Uses Cypher Query Language (CQL) for graph queries.
Supports deep relationships and complex connections.
Easily scales for recommendation engines and fraud detection.
Use Cases:
LinkedIn friend suggestions.
Fraud detection in banking.
Real-time product recommendations.
2. Document Databases – Flexible & Scalable
Document databases store semi-structured data in JSON-like documents.
Example: A product catalog where each item has different attributes (brand, size, category, etc.).
Key Benefits:
Schema-less flexibility – Ideal for dynamic and unstructured data.
High scalability – Handles large-scale applications efficiently.
Nested document support – Eliminates the need for complex joins.
MongoDB – The Most Popular Document Database
Features:
Stores JSON-like documents with flexible schema.
Supports horizontal scaling for big data workloads.
Indexes optimize performance for fast lookups.
Use Cases:
E-commerce product catalogs (Amazon, Shopify).
Content management systems (WordPress, Ghost CMS).
IoT and sensor data storage.
3. Key-Value Stores – Ultra-Fast Lookups
Key-value databases store data as simple key-value pairs, making them extremely fast.
Example: A caching system where user sessions are retrieved by ID.
Key Benefits:
Low latency – Retrieves values instantly.
Highly scalable – Used in high-traffic environments.
Perfect for caching and real-time session management.
Amazon DynamoDB – Fully Managed Key-Value Store
Features:
Auto-scales to handle millions of requests per second.
Supports strong or eventual consistency.
DAX (DynamoDB Accelerator) provides ultra-fast caching.
Use Cases:
Shopping cart session management (Amazon, Walmart).
Gaming leaderboards (real-time rankings in Fortnite, PUBG).
IoT applications (connected device state storage).
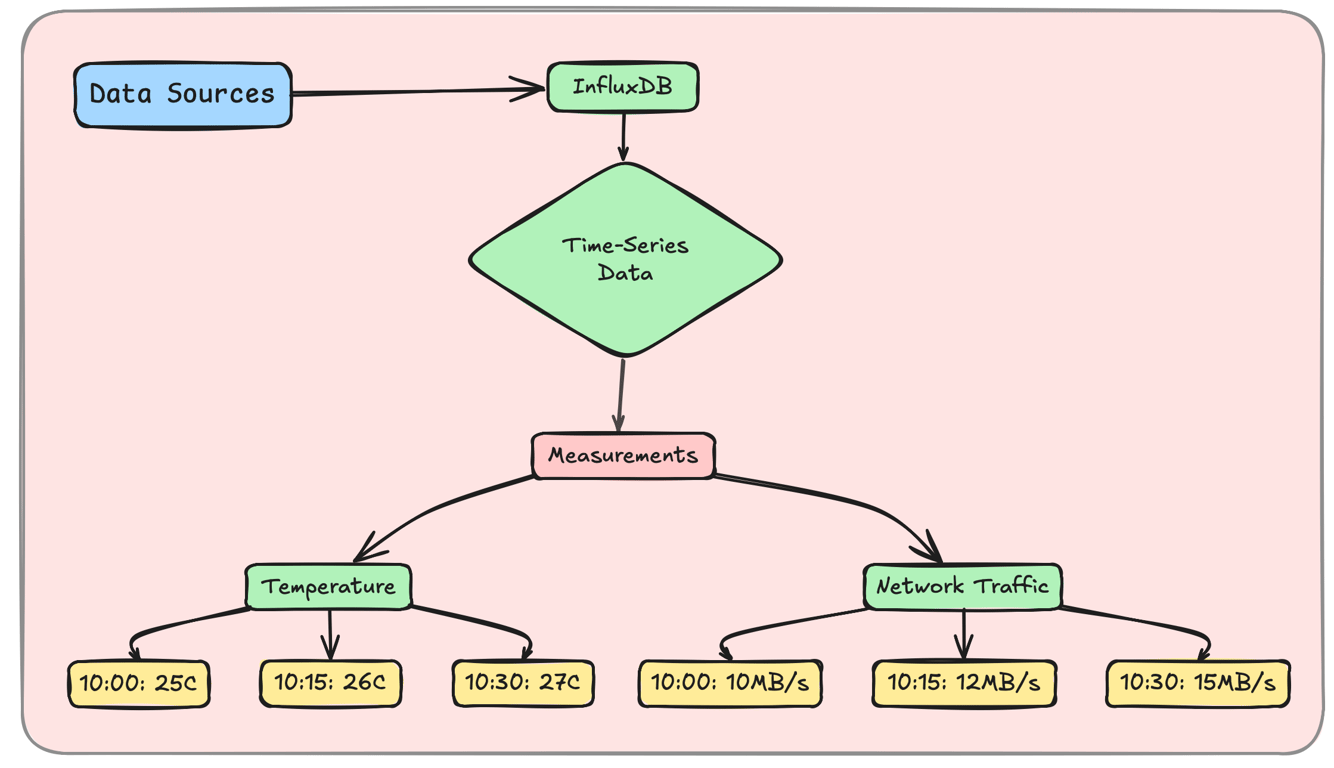
4. Time-Series Databases – Optimized for Time-Stamped Data
Time-series databases specialize in storing and analyzing time-stamped data.
Example: Tracking CPU usage over time in a monitoring system.
Key Benefits:
Efficient storage & retrieval of time-series data.
Optimized for real-time analytics & monitoring.
High compression & retention policies.
InfluxDB – The Leading Time-Series Database
Features:
Handles millions of writes per second.
Supports real-time analytics for IoT, finance, and monitoring.
Provides downsampling for long-term data retention.
Use Cases:
Server monitoring (CPU, memory, network usage).
Stock market & financial data analysis.
IoT sensor data logging.
Choosing the Right NoSQL Database
Database Type
Best For
Graph (Neo4j)
Social networks, recommendations, fraud detection
Document (MongoDB)
E-commerce, content management, flexible schemas
Key-Value (DynamoDB)
Session storage, caching, real-time applications
Time-Series (InfluxDB)
Metrics, logs, financial data, IoT analytics
Real-World Use Cases
1. Social Media & Networking
Graph databases power friend recommendations (Facebook, LinkedIn).
Document databases store user profiles and posts.
2. E-Commerce & Retail
MongoDB manages product catalogs with flexible attributes.
DynamoDB stores user sessions and shopping carts.
3. Monitoring & IoT Applications
InfluxDB tracks system performance metrics.
DynamoDB stores real-time IoT sensor data.
Conclusion
NoSQL databases provide scalability, flexibility, and high performance for modern applications.
Graph databases (Neo4j) handle complex relationships.
Document stores (MongoDB) offer schema flexibility.
Key-Value stores (DynamoDB) ensure ultra-fast lookups.
Time-Series databases (InfluxDB) specialize in time-stamped data.
Next, we’ll explore Designing a Search System – Elasticsearch, Inverted Index, Ranking Algorithms.


