The Growing Pains of a Viral App
Ankit built a startup. His app gained traction, but as users increased, the database slowed down.
Queries took longer, and some requests even timed out. Upgrading the server wasn’t enough.
The solution? Database scaling techniques – sharding, partitioning, and replication – ensuring smooth performance under heavy loads.
What is Database Scaling?
Scaling a database means improving its ability to handle growing amounts of data and traffic efficiently. But how does scaling for a database works? We can understand this better by knowing the types of it:
Two Types of Scaling:
Vertical Scaling (Scaling Up): Upgrading the existing server (CPU, RAM, SSD).
Horizontal Scaling (Scaling Out): Distributing data across multiple servers.
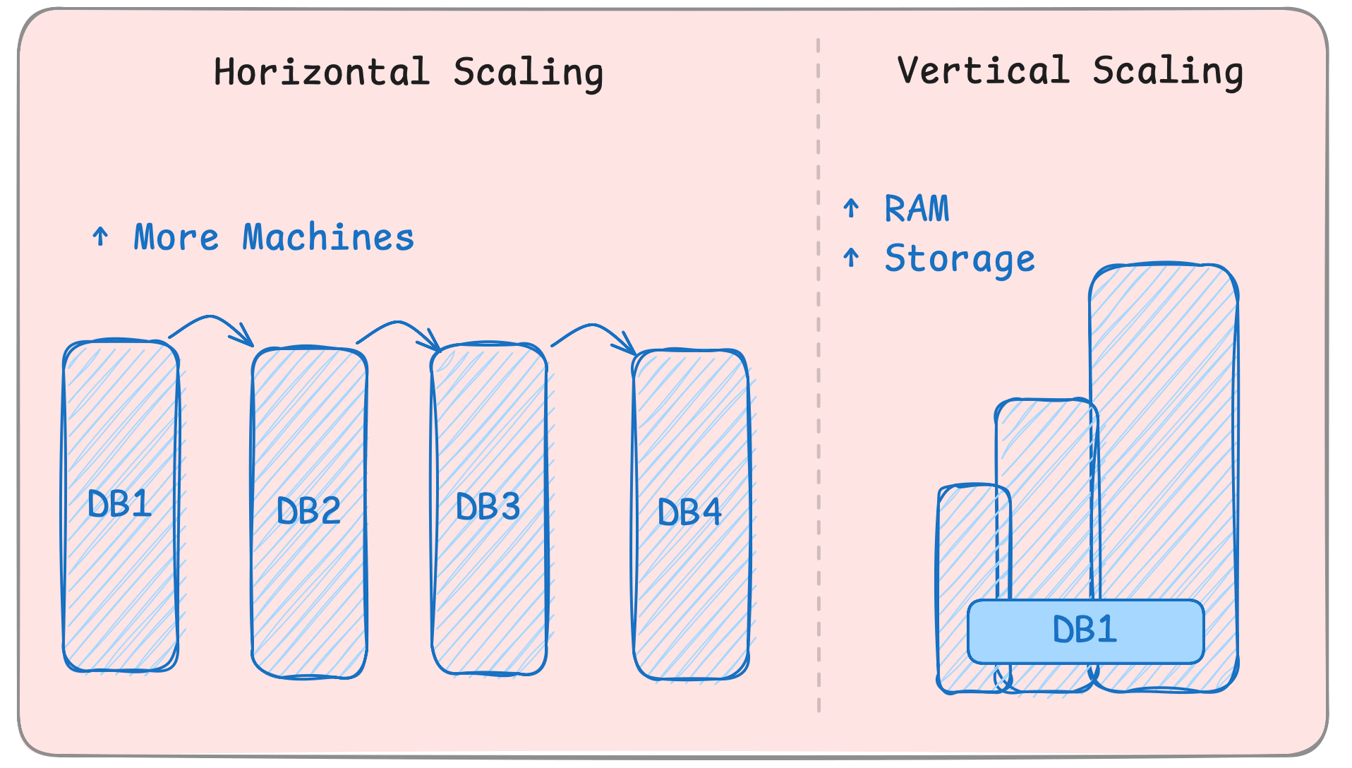
Horizontal scaling is more effective for large applications, and it requires sharding, partitioning, or replication.
Sharding – Splitting Data Across Servers
1. What is Sharding?
Sharding splits a large database into smaller, independent databases called shards.
Each shard stores a portion of the data, reducing the load on any single database server.
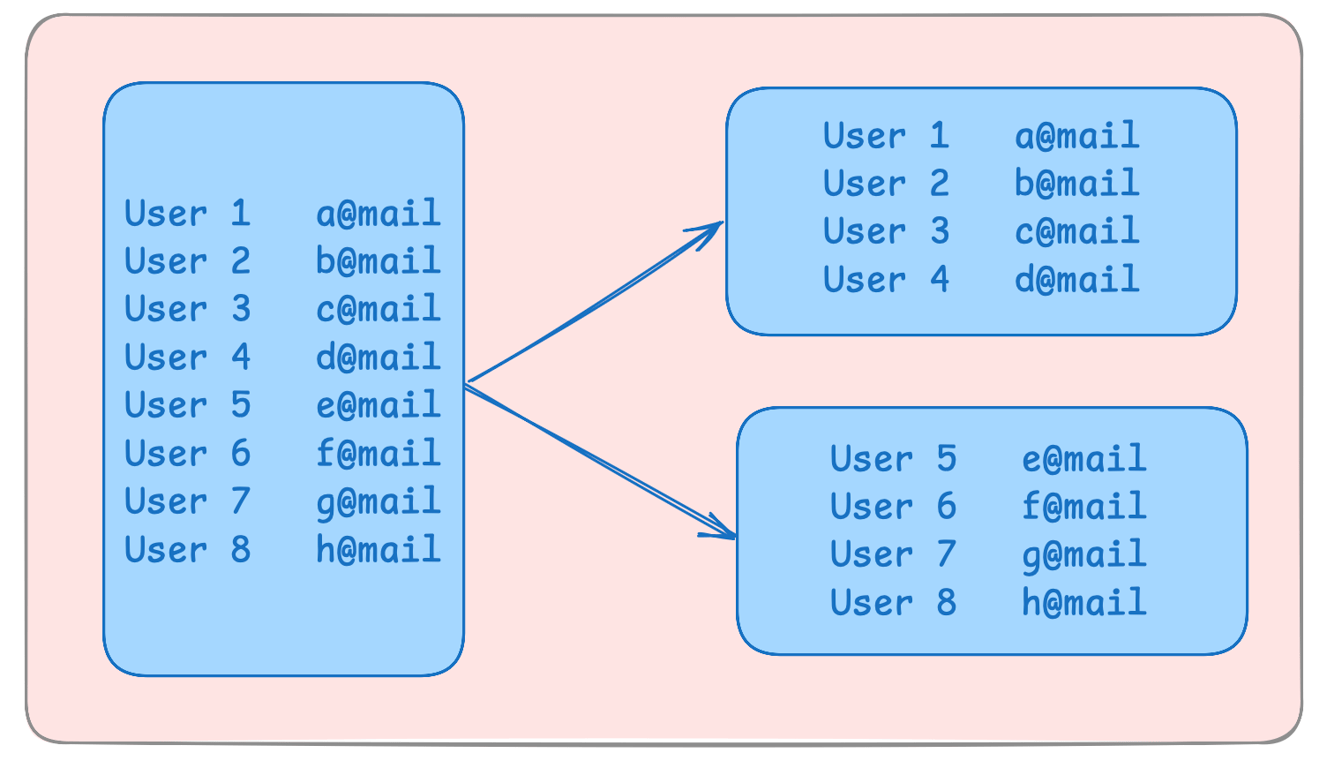
2. Types of Sharding
1. Range-Based ShardingDivides data based on a key range (e.g., User IDs 1-1000 on Shard 1, 1001-2000 on Shard 2). ✔ Simple to implement. ✖ Uneven data distribution can overload a shard.
Uses a hash function to distribute data evenly across shards. ✔ Prevents uneven data distribution. ✖ Harder to rebalance when adding new shards.
Uses a lookup table to map records to the correct shard. ✔ More flexible. ✖ Adds overhead with maintaining the lookup table.
Partitioning – Organizing Data Within a Database
1. What is Partitioning?
Partitioning divides a database table into smaller, manageable sections called partitions, improving performance.
Unlike sharding, partitions remain on the same database server but help optimize queries.

2. Types of Partitioning
1. Range PartitioningSplits data based on a column range (e.g., transactions before 2020 in Partition A, after 2020 in Partition B). ✔ Speeds up queries for specific ranges. ✖ Imbalance if data isn’t evenly distributed.
Groups related data into partitions (e.g., orders from USA in Partition A, Europe in Partition B). ✔ Optimized for queries filtering by categories. ✖ Requires careful planning.
Uses a hash function to assign rows to partitions. ✔ Evenly distributes data. ✖ Harder to control how data is split.
Replication – Ensuring Data Availability
1. What is Replication?
Replication creates copies of a database across multiple servers to improve availability and fault tolerance.
If one server fails, another takes over without downtime.
2. Types of Replication
1. Master-Slave ReplicationA primary (master) database handles writes; secondary (slave) databases handle reads. ✔ Improves read performance. ✖ Delays in syncing data between master and slaves.
Multiple databases handle both read and write requests. ✔ High availability. ✖ Complex conflict resolution.
All nodes act as equals and sync changes among each other. ✔ No single point of failure. ✖ Higher overhead for synchronization.
Choosing the Right Scaling Approach
Scaling Technique
Best For
Sharding
Large-scale applications needing distributed data storage.
Partitioning
Optimizing queries within a single database.
Replication
High availability and disaster recovery.
Real-World Use Cases
1. E-Commerce Platforms
Sharding distributes product databases across regions.
Replication ensures checkout remains available even during failures.
2. Social Media Apps
User profiles are partitioned by country.
Sharding handles billions of posts efficiently.
3. Financial Systems
Replication keeps transaction data redundant for security.
Partitioning organizes historical records efficiently.
Conclusion
Scaling a database ensures high performance and availability.
Sharding distributes data across multiple servers.
Partitioning optimizes large tables within a single database.
Replication ensures redundancy and failover protection.
Next, we’ll explore Eventual Consistency & Distributed Data Stores – Cassandra, DynamoDB, CRDTs.


