The Day a Cloud Server Failed
A banking app suddenly went offline. Millions of users were locked out.
The issue? A critical database server crashed, and there was no failover mechanism.
With fault tolerance and high availability, systems can withstand failures, recover automatically, and remain accessible under any conditions.
What is Fault Tolerance?
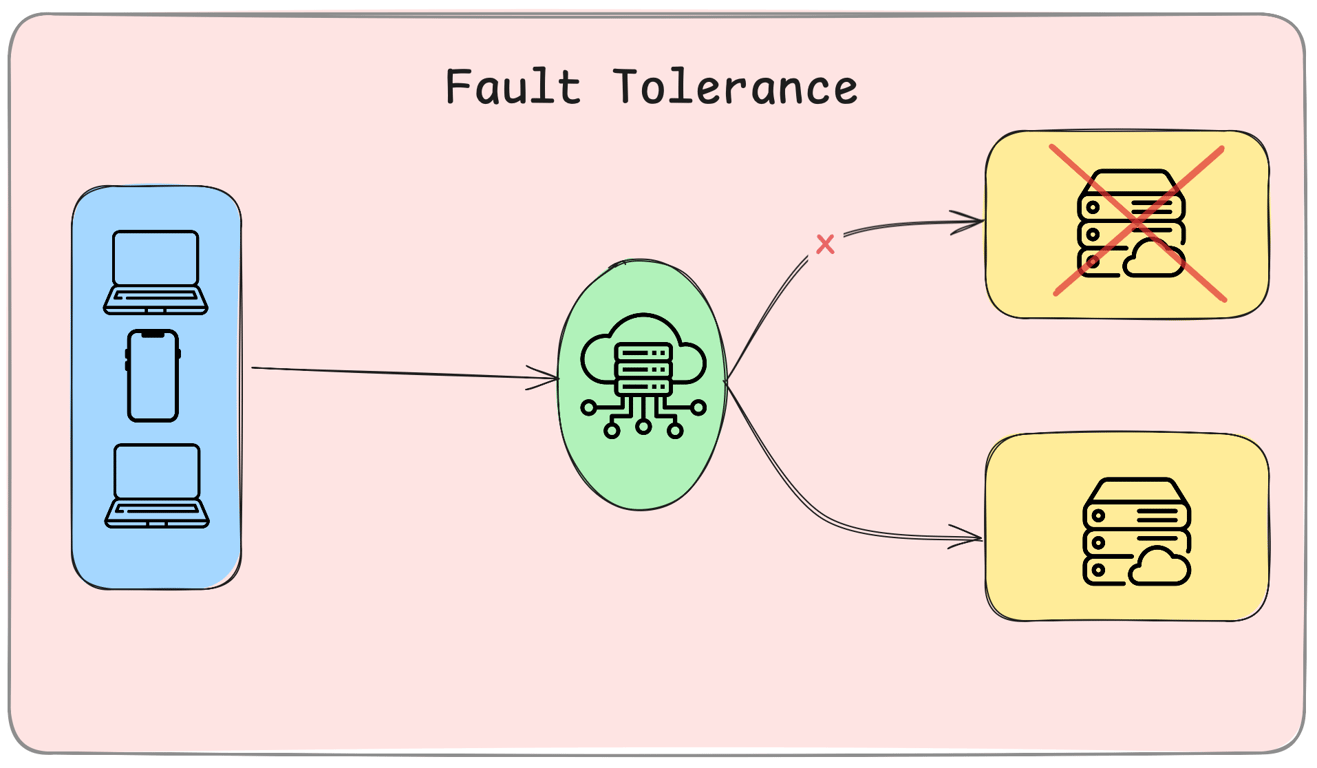
Fault tolerance is a system’s ability to continue operating despite hardware, software, or network failures.
A fault-tolerant system prevents downtime, ensuring seamless operation.
Example: A cloud database with automatic failover continues working even if a primary node fails.
What is High Availability?
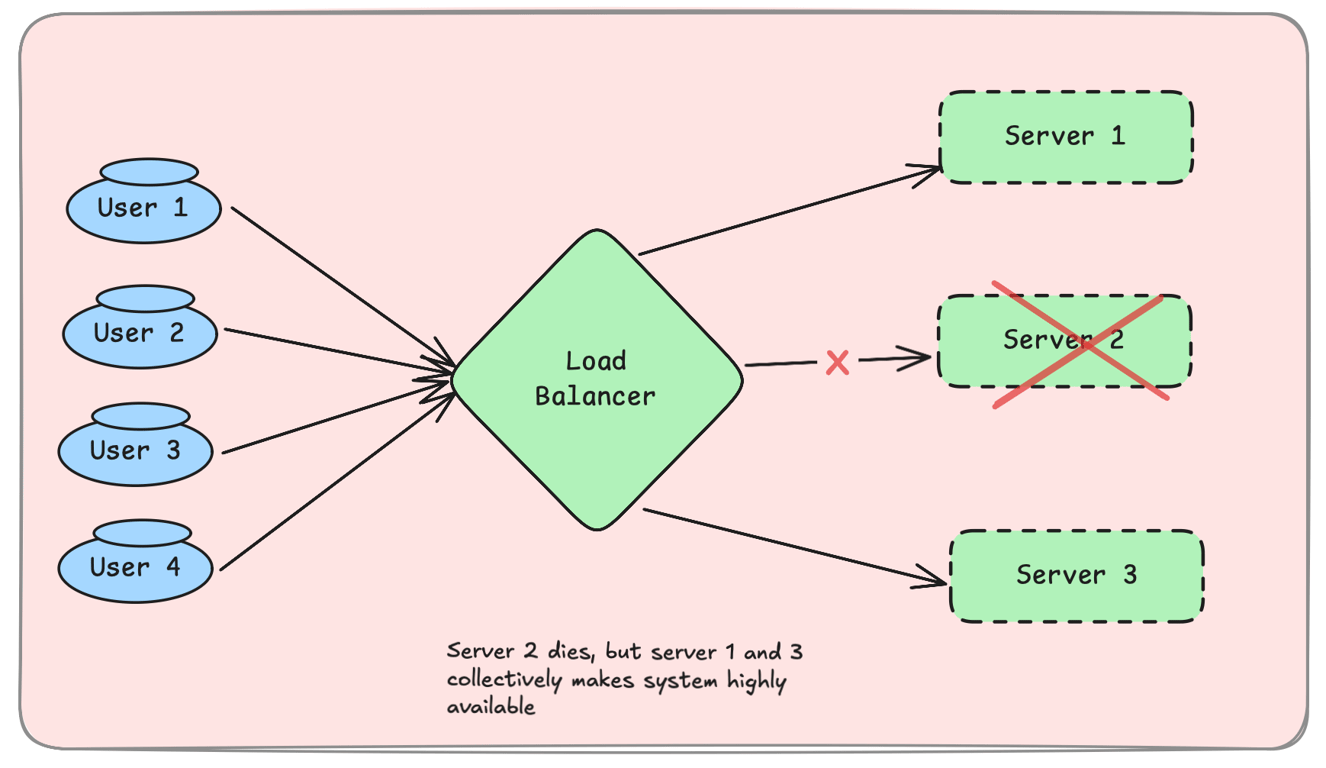
High availability (HA) ensures minimal downtime by distributing workloads across multiple redundant systems.
Example: A website running on multiple servers with load balancing remains accessible even if one server crashes.
Key Strategies for Fault Tolerance & High Availability
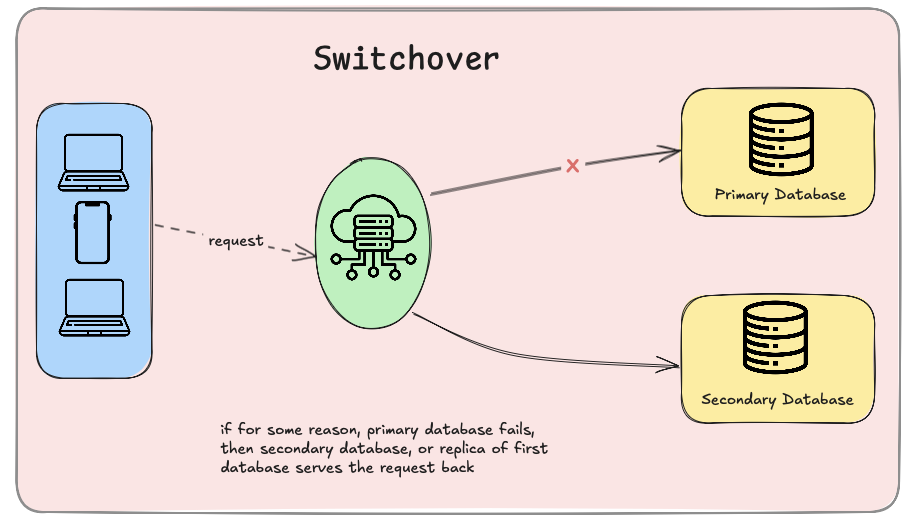
1. Failover Strategies – Automatic Switchover to Backup Systems
Failover ensures if a primary system fails, a backup system takes over instantly.
✔ Cold Failover: Backup system activates manually (slow but cost-effective). ✔ Warm Failover: Standby system is partially active, reducing downtime. ✔ Hot Failover: Fully active backup instantly takes over (zero downtime).
Example: AWS RDS uses hot failover to switch to a replica database instantly.
2. Load Balancing – Distributing Traffic Efficiently
Load balancers direct incoming traffic across multiple servers to prevent overloading. We have already discussed this in detail, but again let's have a short recap.
Example: An e-commerce site uses AWS Elastic Load Balancer (ELB) to ensure millions of requests are evenly distributed.
Techniques:
Round Robin – Distributes requests sequentially.
Least Connections – Routes to the least busy server.
Consistent Hashing – Ensures session persistence.
For reference you may go to previous lessons of ours on load balancing: Here
3. Self-Healing Systems – Automatic Recovery from Failures
Self-healing systems detect failures and recover without manual intervention.
Example: Kubernetes automatically restarts failed containers.
Self-Healing Mechanisms:
Auto Restart: Failing services are restarted automatically.
Instance Replacement: Cloud instances are replaced when unhealthy.
Database Healing: Failed replicas are rebuilt automatically.
(This will be coming more in detail, in further blog of Kubernetes too..)
4. Data Replication – Ensuring Redundancy
Data replication creates multiple copies of data across different locations for resilience.
Types of Replication:
Synchronous Replication: Ensures data consistency across replicas.
Asynchronous Replication: Faster but may cause minor data delays.
Example: Google Cloud Spanner uses multi-region replication to ensure zero data loss.
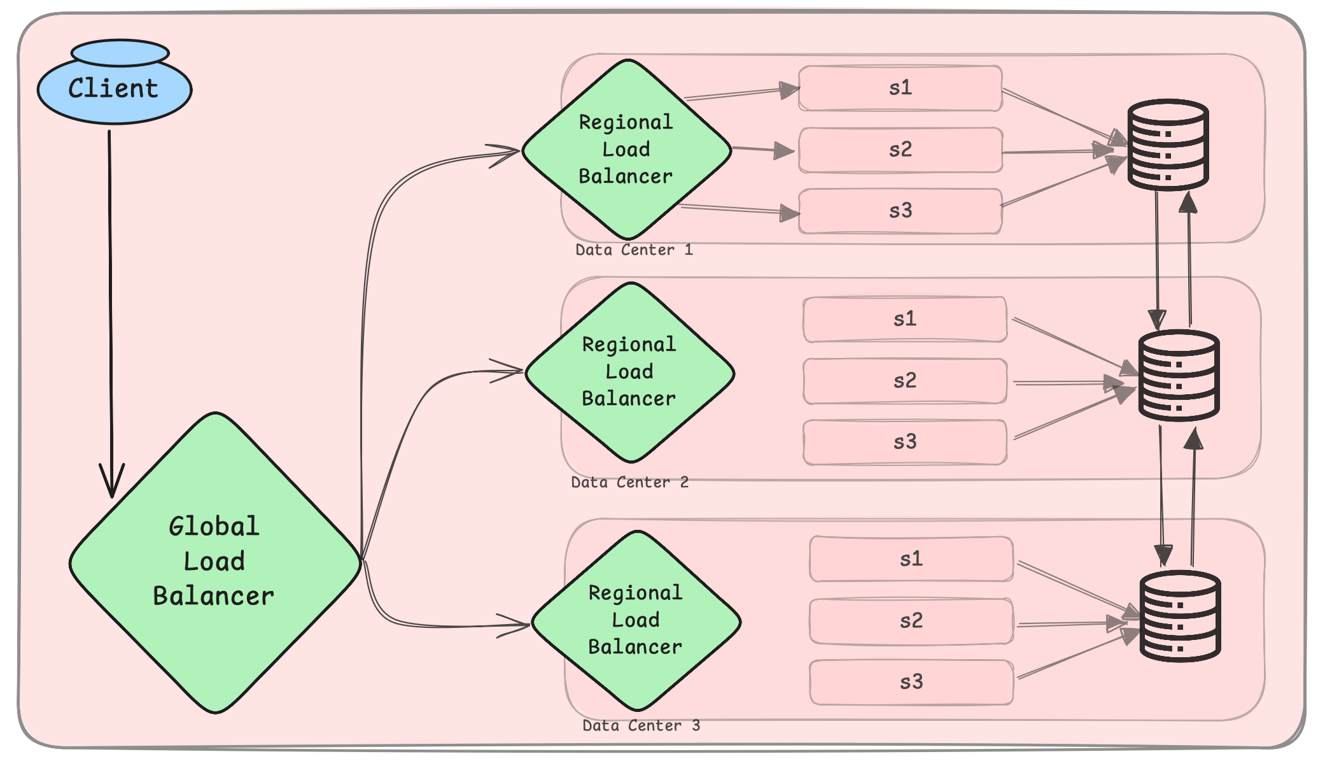
5. Geo-Redundancy – Disaster Recovery Across Regions
Geo-redundancy duplicates services and data across different geographic locations.
Example: Netflix deploys services in multiple AWS regions to prevent regional outages.
Real-World Use Cases
1. Cloud Computing (AWS, GCP, Azure)
Auto-scaling and failover mechanisms prevent downtime.
Geo-distributed cloud regions ensure redundancy.
2. Banking & Financial Services
Active-passive database replication ensures transactional integrity.
Load balancers distribute high-traffic requests.
3. Streaming Platforms (Netflix, YouTube)
CDN-based redundancy prevents video buffering.
Self-healing services restart failed streaming nodes.
Conclusion
Building fault-tolerant and highly available systems ensures resilience against failures.
Failover strategies enable seamless backup transitions.
Load balancing prevents single points of failure.
Self-healing mechanisms automate failure recovery.
Replication and geo-redundancy ensure data safety and disaster recovery.
Next, we’ll explore Consensus Algorithms & Distributed Coordination – Paxos, Raft, 2PC, Gossip Protocol.


