The Challenge of Data Consistency
A ride-sharing app faced a serious issue: some users saw canceled rides still marked as active.
The problem? Inconsistent data across distributed databases.
The solution? Proper consistency models like ACID, BASE, Event Sourcing, and CQRS to ensure accurate and reliable data storage.
What is Data Consistency?
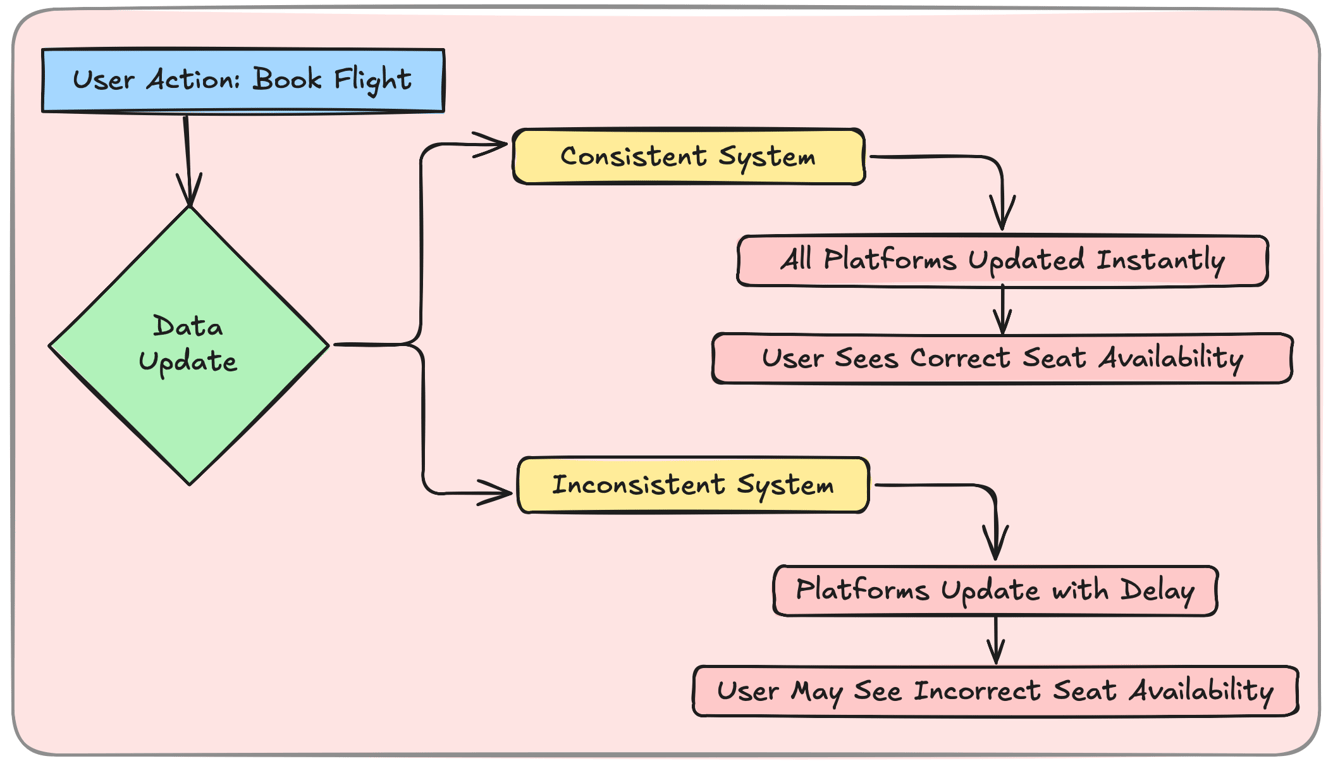
Data consistency ensures that all users see the correct and up-to-date information across all systems.
Example: When a customer books a flight, the seat availability updates instantly across all platforms.
Key Challenges:
Latency vs. Consistency – Ensuring fast responses without stale data.
Distributed Databases – Synchronizing data across multiple servers.
Concurrency Control – Handling multiple simultaneous updates safely.
ACID – Strong Consistency for Databases
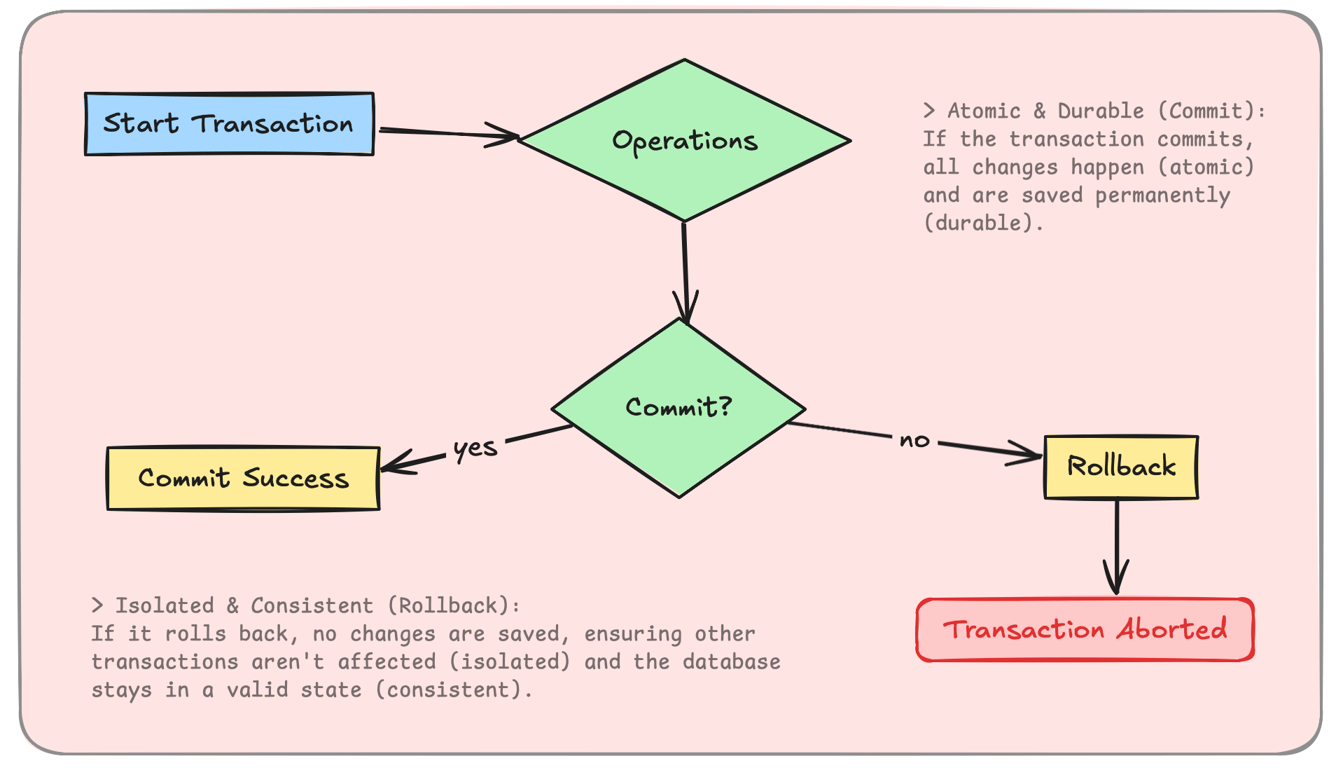
ACID (Atomicity, Consistency, Isolation, Durability) ensures strong transactional integrity.
Key Principles:
Atomicity: A transaction is either fully completed or fully rolled back.
Consistency: The database remains in a valid state after transactions.
Isolation: Transactions execute independently without conflicts.
Durability: Once committed, data is permanently saved.
Example: A banking transaction either fully succeeds or fully fails (no half-updated balances).
BASE – Eventual Consistency for High Scalability
BASE (Basically Available, Soft state, Eventual consistency) is used in distributed systems where strong consistency is relaxed for performance.
Key Principles:
Basically Available: System remains operational even during failures.
Soft State: Data changes over time without strict consistency.
Eventual Consistency: All replicas sync over time but may have temporary inconsistencies.
Example: Social media posts may appear instantly for one user but take seconds to sync globally.
Event Sourcing – Tracking Changes as Events
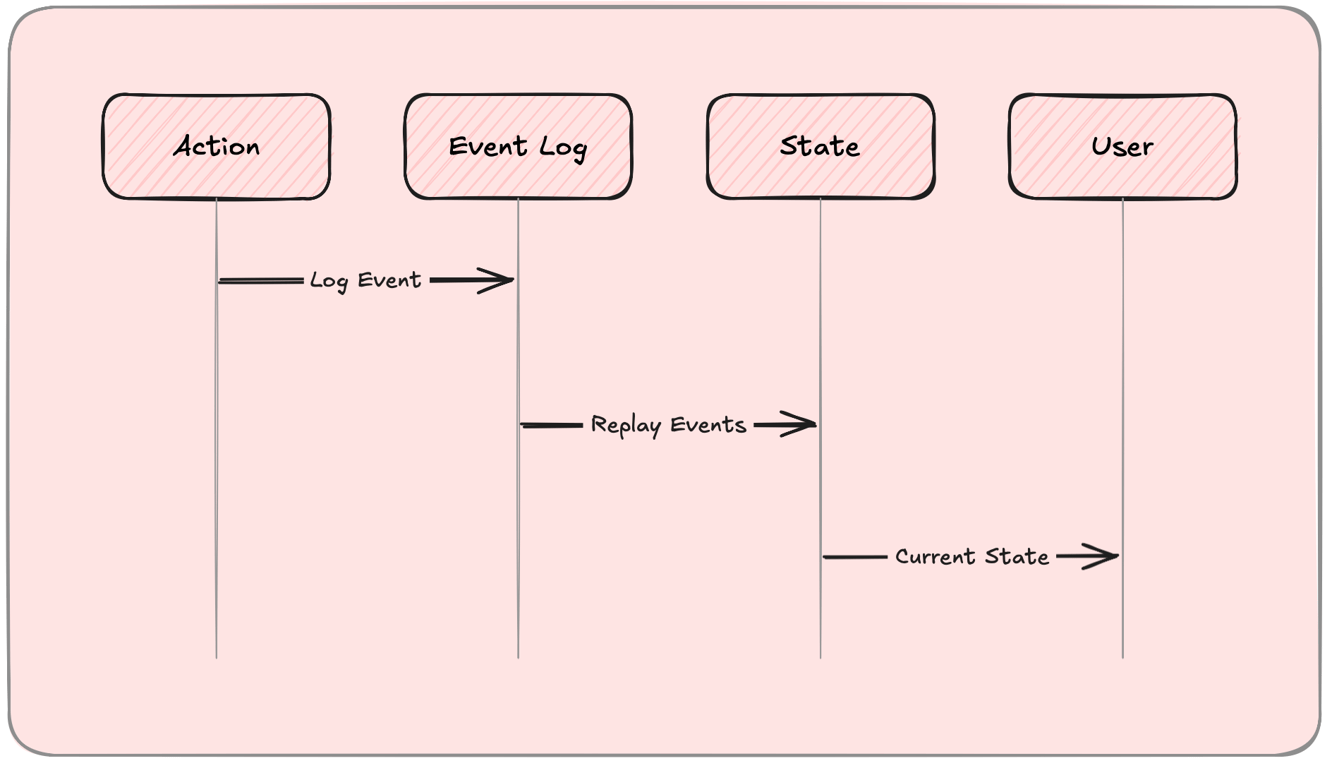
Event Sourcing stores every change as an immutable event, instead of just the latest state.
How It Works:
Every action (e.g., order placed, payment completed) is logged as an event.
The system reconstructs the current state by replaying these events.
This enables auditability, rollback, and time-travel debugging.
Example: A payment system logs each step (initiated → verified → completed) as separate events.
CQRS – Separating Reads and Writes
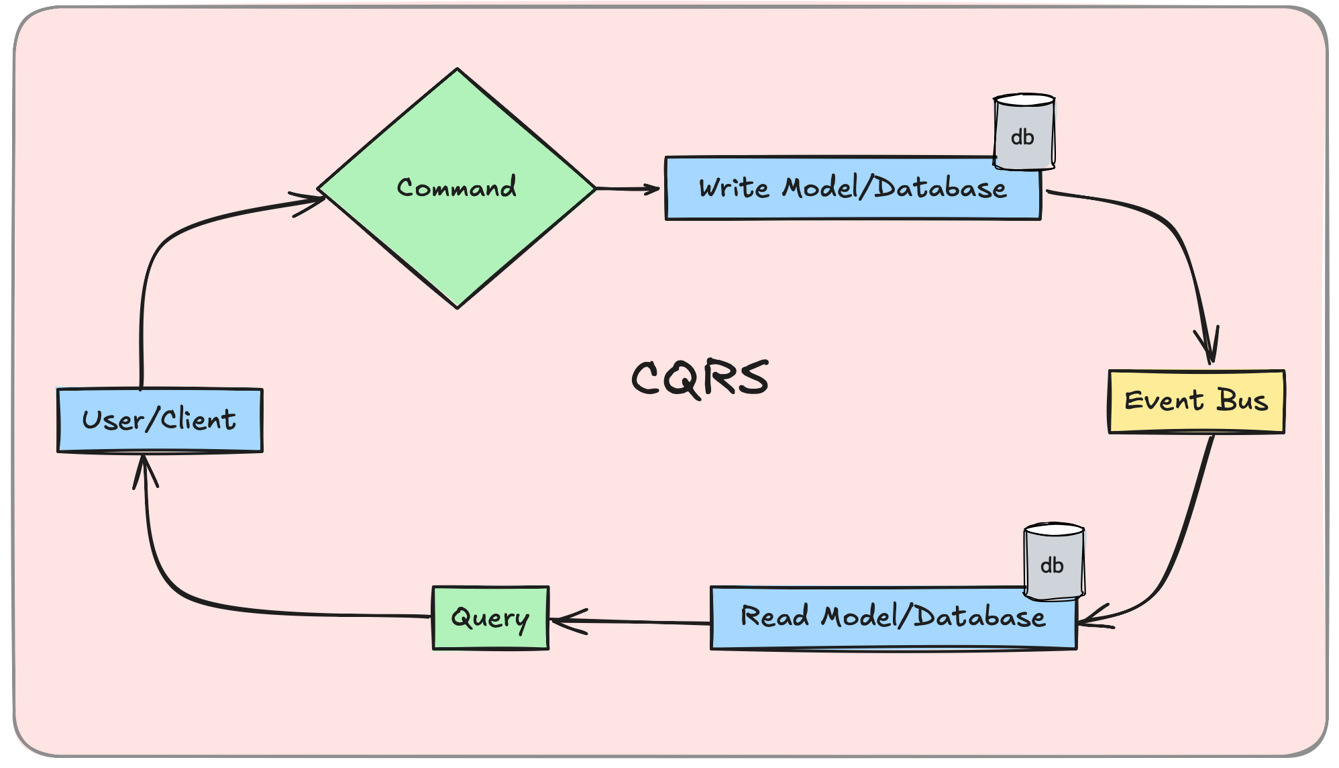
CQRS (Command Query Responsibility Segregation) splits read and write operations into separate databases.
Key Benefits:
Faster Reads: Optimized for retrieving data efficiently.
Efficient Writes: Handles complex data updates separately.
Scalability: Independent scaling of read and write services.
Example: An e-commerce system uses one database for processing orders and another for customer dashboards.
Choosing the Right Strategy
Strategy
Best For
ACID
Financial transactions, banking, stock trading
BASE
Social media, real-time analytics, NoSQL databases
Event Sourcing
Audit logs, tracking changes, domain-driven design
CQRS
Large-scale applications with complex queries
Real-World Use Cases
1. Banking & Payments
ACID transactions ensure accurate balances.
Event Sourcing logs every payment step.
2. E-Commerce & Inventory Systems
CQRS optimizes order processing vs. customer analytics.
BASE consistency allows real-time product updates.
3. Social Media & Messaging Apps
BASE model ensures messages eventually sync.
Event Sourcing logs all interactions (likes, comments, shares).
Conclusion
Different storage strategies balance consistency, availability, and scalability.
ACID ensures strict consistency for critical transactions.
BASE provides high availability with eventual consistency.
Event Sourcing logs every change for better traceability.
CQRS separates read and write concerns for high-scale applications.
Next, we’ll explore Idempotency & Designing Reliable APIs – Handling Retries, Request Deduplication.


